Search the Docs
Elasticsearch at Read the Docs
Navigate with [ space ]
$ whoami
- Santos Gallegos
- Read the Docs
- developer (web)
- @stsewd

About Read the Docs
- Build and host your documentation
- Created around 2010
- More than 100K projects
- Extra features
- https://readthedocs.org/

Server Side Search
- Better search experience
- Sphinx, MkDocs (partially)
- Search across sub-projects
- Ranking and ignoring pages
- Analytics
- API
-
"exact match"prefix*fuzzy~2
A brief history about search at RTD
- 2013 Rob Hudson @robhudson (#493)
-
2018
Safwan Rahman
@safwanrahman
https://blog.readthedocs.com/search-improvements/ -
2019
Vaibhav Gupta
@dojutsu-user
https://blog.readthedocs.com/improved-search-and-search-as-you-type/ - 2020 - 2021 Me!
Indexing Process
Parse configuration file
↓
Sphinx build → JSON metadata & HTML
↓
Track files with their ignore & ranking options
↓
JSON metadata → Searchable text
Configuration File
.readthedocs.yaml
version: 2
sphinx:
configuration: docs/conf.py
python:
version: 3.8
install:
- requirements: docs/requirements.txt
search:
ranking:
api/v1/*: -5
api/v2/*: 5
ignore:
- search.html
- 404.html
search:
ranking:
api/v1/*: -5
api/v2/*: 5
ignore:
- search.html
- 404.html
https://docs.readthedocs.io/en/stable/config-file/v2.html#search
Indexing the content
- Get metadata from each file or the file itself
- Extract searchable content based on heuristics
- Remove navigation nodes and line numbers from code-blocks
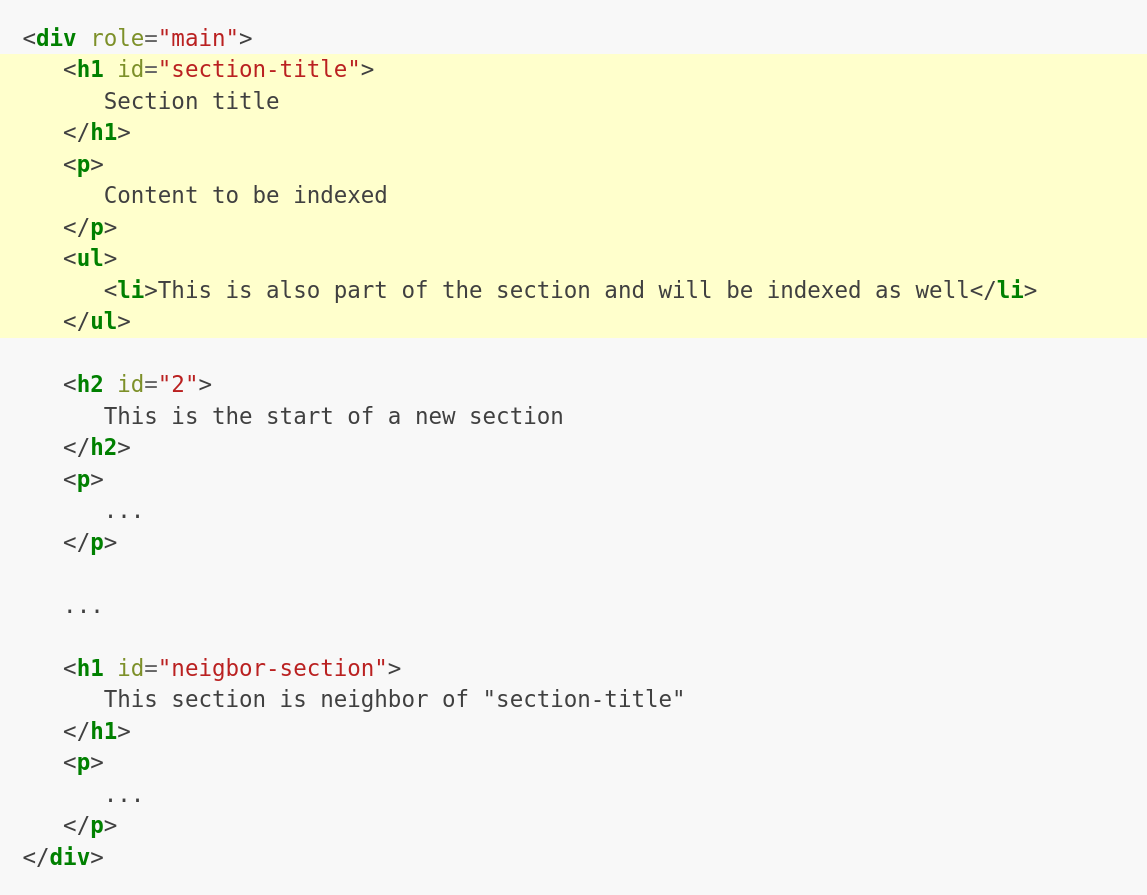
- Divide content into sections and domains (Sphinx)
readthedocs/search/parsers.py
readthedocs/search/documents.py
https://docs.readthedocs.io/page/development/search-integration.html
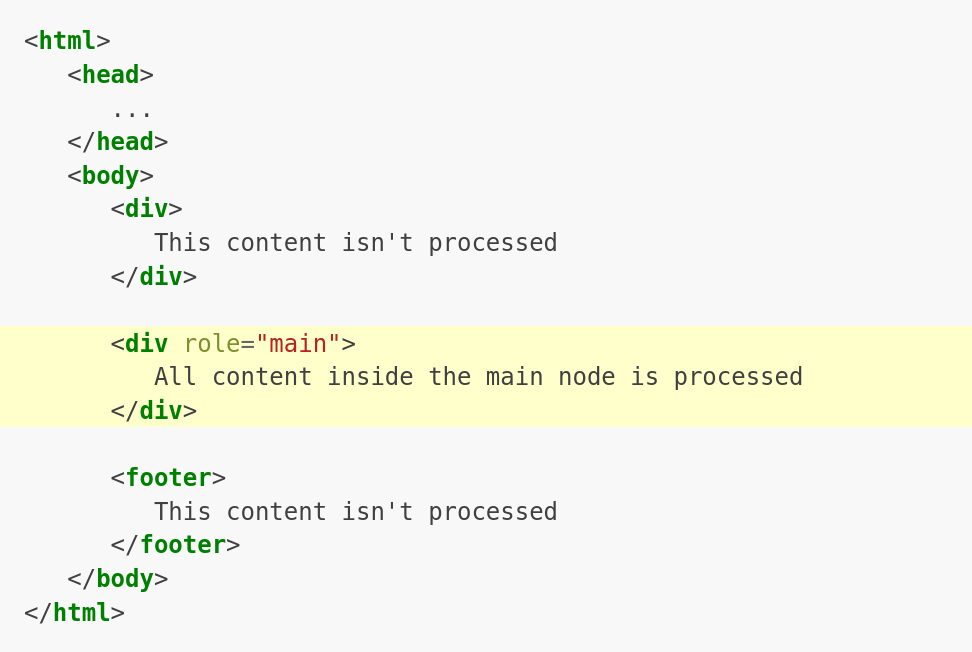



Ignoring pages
Ignored page → not indexed page
Ranking pages
- Ranking can be done at index or search time
- Ranking at search time with function score query
- Painless script
- Map each ranking [-10, 10] to a score
- Play nice with custom boosting
search:
ignore:
# Internal documentation
- development/design/*
- search.html
- 404.html
ranking:
# Deprecated content
api/v1.html: -1
config-file/v1.html: -1
# Useful content, but not something we want most users finding
custom_installs/*: -6
changelog.html: -6
Painless script
// ranking: [0.01, .. 0.8, 1, 1,3, .. 2]
int rank =
doc['rank'].size() == 0 ?
0 : (int) doc['rank'].value;
return params.ranking[rank + 10] * _score;
https://www.elastic.co/guide/en/elasticsearch/reference/master/modules-scripting-painless.html
Overriding the default search
- Hijack the search call via Javascript
- Keep a reference to the old search for backup
- If you ignore a page, you may still see it in the results from the backup search
https://docs.readthedocs.io/page/development/search-integration.html#overriding-the-default-search
var original_search = Search.query;
function search_override(query) {
var results = fetch_resuls(query);
if (results) {
for (var i = 0; i ≤ results.length; i += 1) {
var result = process_result(results[i]);
Search.output.append(result);
}
} else {
original_search(query);
}
}
Search.query = search_override;
$(document).ready(function() {
Search.init();
});
API
- DRF wrapper around the ES response
- Serializers & Pagination
docs.readthedocs.io/_/api/v2/search/?project=docs&version=latest&q=api
readthedocs/search/api.py
https://docs.readthedocs.io/page/server-side-search.html#api
Problems
And solutions!Latency 🐌
-
ES cloud (AWS) → RTD app (Azure) - ES cloud (Azure) → RTD app (Azure)
-
ES cloud (AWS zone B) → RTD app (AWS zone A) - ES cloud (AWS zone A) → RTD app (AWS zone A)
Partial terms results
- Search for code and words
- theme, themes, temes, temes~1
- python.*, *.fail_on_warning
- test, testing
- index, reindex, indexing, reindexing
- Simple query string query
- Multi-match query (fuzziness AUTO:4,6)
- Wildcard query
- We can combine multiple types of queries, but we don't always want to combine them all.
- Single/simple search terms vs complex terms.
https://www.elastic.co/guide/en/elasticsearch/reference/current/full-text-queries.html
- Wildcard queries over Text fields can be slow...
- Wildcard queries over Wildcard fields are fast!
- Wildcard or Text field?...
- Both! Multi fields (#7613)
https://www.elastic.co/guide/en/elasticsearch/reference/current/keyword.html#wildcard-field-type
Other things
- Sponsored account of Elastic Cloud
- Cached results via Cloudflare
-
Search as you type
https://readthedocs-sphinx-search.readthedocs.io/
What's next?
- Better results for partial terms #7613
- Weight page views into results #7297
- Use SSS by default for MkDocs
- Enable search indexing for pull requests previews?
- Ignore and ranking per sections?
- Better display for results from code blocks? #7112
- Search for images and code snippets?
- Search by files patterns and other facets?